
SkillStack Lab(スキスタ)運営者のスタックです。
今回は、自社のマニュアルや社内規定をAIに読み込ませて、社内からの問い合わせ対応を自動化するチャットボットを作りたいと考えている管理部門や情シス担当者の方に向けて解説します。
dify ナレッジ 使い方とWEBで検索して、PDFなどの社内文書をアップロードし、RAGと呼ばれる仕組みを構築しようとしている方は多いでしょう。
しかし、ただデータを入れるだけでは、AIが的外れな回答をするハルシネーションが起きたり、検索テストでの精度が上がらずに現場で全く使われないという壁にぶつかりがちです。
チャンク分割などの技術的な設定や体系的な学習を行わないまま進めると、せっかく導入したシステムが無駄になってしまいます。
そこでこの記事では、本当に実務で使える精度の高いAIチャットボットを作るための具体的な手順と注意点をお伝えしますね。
- 現場で使えないAIを生み出してしまう根本的な原因とハルシネーションの罠
- 回答精度を劇的に向上させるためのチャンク分割やインデックス設定のコツ
- 運用後の属人化を防ぐための検索テストと社内標準ルール策定の重要性
- 無駄なエラーを回避し最短ルートでRAGを構築するための体系的な学習方法

Difyのナレッジの使い方と基本手順
Difyを使って自社専用のAIを作る際、ナレッジ機能はまさに心臓部と言える重要な機能です。
ここでは、社内のドキュメントをどのようにAIに読み込ませ、それがどう機能するのかという基本的な手順と、その背後にあるメリットや陥りがちな罠について詳しく解説していきます。
設定画面の向こう側でAIがどのような処理を行っているのかをイメージできるようになると、構築の精度がグッと上がりますよ。
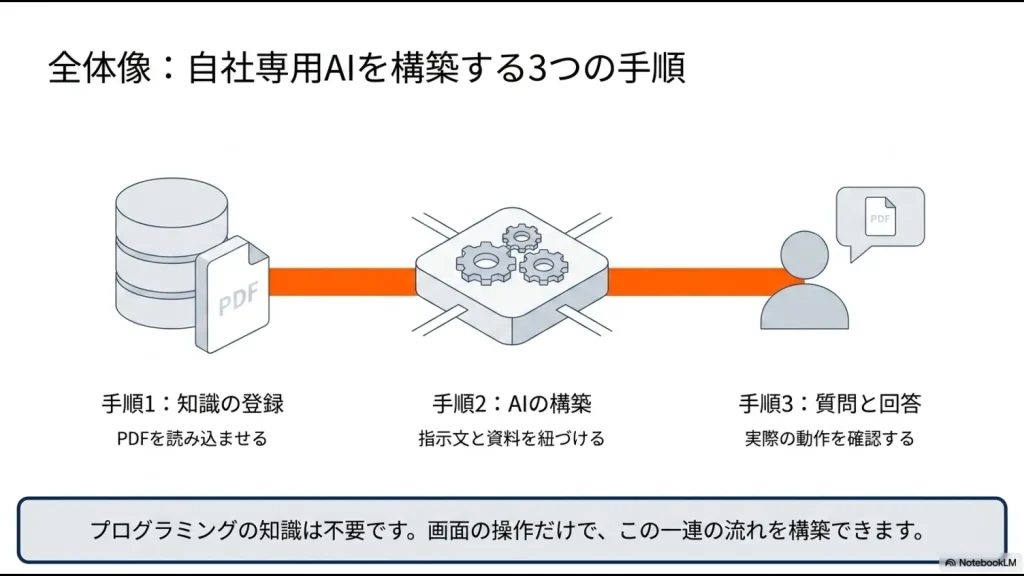
社内文書をAI化するRAGのメリット
管理部門や情シスにいると、「あの申請書の書き方を教えて」「就業規則のあの項目について知りたい」「経費精算の締め日はいつだっけ?」といった、社内からの同じような問い合わせに毎日時間を奪われていませんか?
Difyのナレッジ機能を活用して構築する「RAG(検索拡張生成)」という仕組みは、まさにこうした課題を解決する強力な武器になります。
RAGとは、一般的なAIに、自社独自の非公開データや社内文書を検索・参照させる技術のことです。
業務効率化の起爆剤としてのRAG
通常のChatGPTのようなAIは、インターネット上の広範なデータで学習しているため一般的な質問にはうまく答えられますが、「御社のローカルルール」については一切知りません。
だからこそ、RAGという技術を使ってAIに「自社のルールブック」を渡してあげる必要があるんですね。
通常のAIは世の中の一般的な知識しか持っていませんが、RAGを使えば「自社のルールに基づいた専属のアシスタント」を生み出すことができるわけです。
マニュアルや過去のQ&A履歴、稟議書の書き方ガイドなどをAIのナレッジベースに格納しておくことで、社員からの質問に対して24時間365日、AIが社内文書という根拠に基づいた正確な回答を即座に返してくれるようになります。
これにより、私たちバックオフィス部門は「調べて答えるだけ」のルーチンワークから解放されます。
空いた時間を、システムの改善や全社的なDX推進といった、より付加価値の高いコア業務に集中できるようになるのが、RAGを導入する最大のメリットかなと思います。

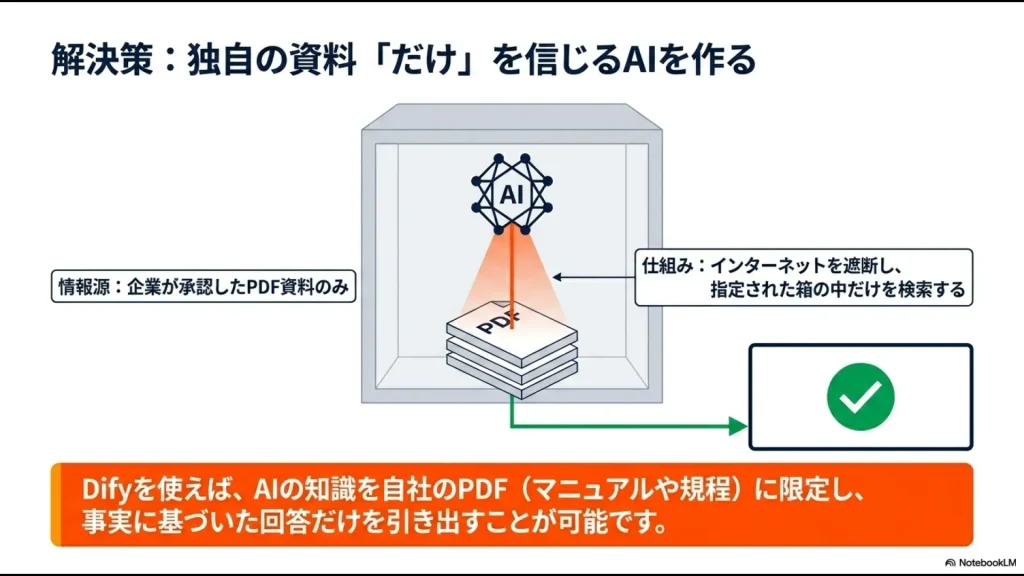
PDFを読み込ませる基本のデータ登録
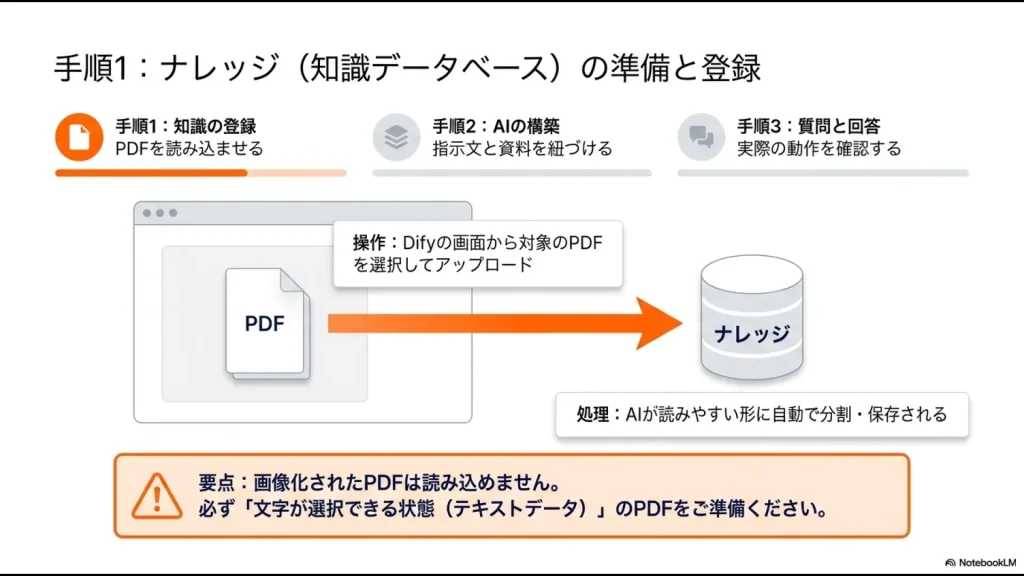
では、実際にDifyでナレッジを構築するにはどうすればいいのでしょうか。最初のステップは、社内に眠っているPDFやWord、テキストファイルなどのデータをDifyにアップロードすることです。
Difyの管理画面からナレッジの作成メニューを選び、対象のファイルを選択してインポートするだけの簡単な操作で完了します。
対応フォーマットと前処理の重要性
Difyは非常に柔軟なプラットフォームであり、私たちが日常業務で使っている多種多様なファイル形式をサポートしています。(出典:Dify公式ドキュメント『ナレッジ – Dify Docs』)によれば、テキスト形式だけでなく、PDF、Markdown、Excel、CSVなど様々なデータソースを取り込むことが可能です。
| ファイル形式 | Difyでの扱いやすさと特徴 |
|---|---|
| PDF / DOCX | 社内規定やマニュアルの定番。ただし、複雑な表や段組みがあるとAIがテキストを抽出しにくい場合があります。 |
| Markdown (.md) | 見出し(#)などの構造が明確なため、AIが文脈を理解しやすく最も推奨されるフォーマットです。 |
| CSV / Excel | 過去の問い合わせ履歴など、「一問一答」のFAQデータを一括で読み込ませる際に非常に強力です。 |
社内規定などはPDFで保管されていることが多いですよね。アップロードされたデータは、Difyの内部で自動的にテキストデータとして抽出され、AIが検索しやすい形に処理されます。
ノーコードで直感的に操作できるため、プログラミングの専門知識がない管理部門の方でも、「とりあえずデータを入れる」という基本のデータ登録まではものの数分で完了できるはずです。
この「思い立ったらすぐ試せる手軽さ」こそが、Difyが世界中で支持されている理由の一つですね。
ただ入れただけでは現場で使われない罠
しかし、ここからが非常に重要なポイントになります。PDFをポンとアップロードして、「はい、これで自社専用のAIが完成しました!みんな使ってね!」と現場にリリースしてしまうケースが後を絶ちません。
ですが、元情シスとしてあえて厳しいことを言わせてください。
「検索のノイズ」が引き起こす現場の不信感
ただデータを入れただけで作られたAIは、確実に現場で「使えないシステム」の烙印を押され、誰もアクセスしなくなります。
なぜなら、ドキュメントを丸ごと無造作に投げ込んだだけでは、AIが情報の構造を正しく理解できないからです。
ITの世界には「Garbage In, Garbage Out(ゴミを入れたらゴミが出てくる)」という格言がありますが、まさにこれですね。
例えば、数十ページに及ぶマニュアルの中から、社員が求めている特定の条件に当てはまる部分だけをピンポイントで引き出すことは、初期設定のままでは非常に困難です。
検索結果に不要なノイズ(関係ない章のテキスト)が混ざったり、逆に本当に必要な文脈が途切れたりして、社員が求める「ズバリの回答」が返ってきません。
その結果、数回試した社員は「なんだ、結局AIに聞くより、今まで通り情シスや総務に電話した方が早いじゃないか」と見切りをつけてしまいます。
一度現場からの信頼を失ったシステムを再稼働させるのは、新規導入の何倍も労力がかかってしまうのです。
精度を下げるハルシネーションの恐怖
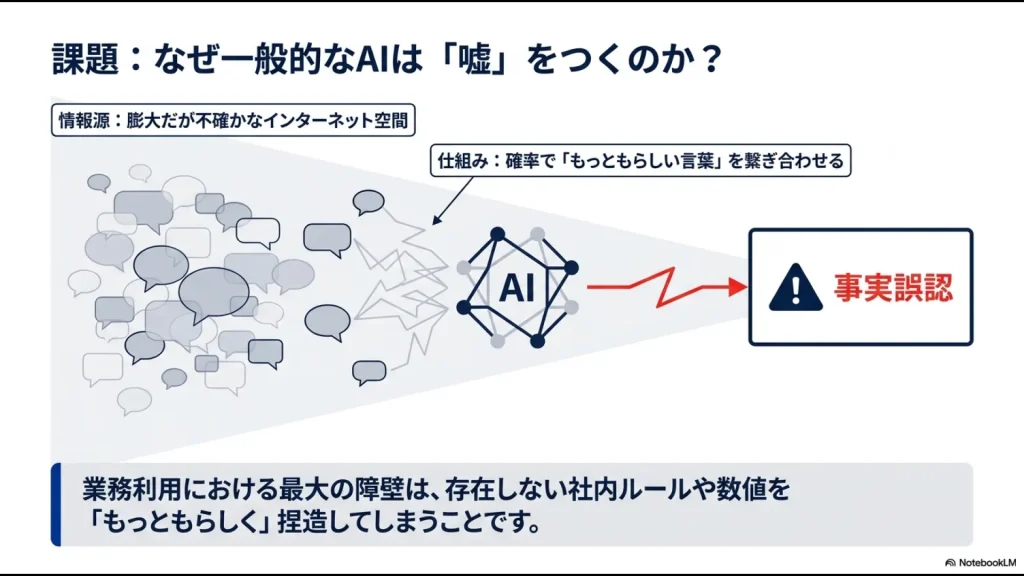
現場で使われなくなる最大の原因であり、私たち管理部門が最も恐れなければならないのが「ハルシネーション(幻覚)」と呼ばれる現象です。
AIが、あたかも事実であるかのように、自信満々で自社のルールには存在しない嘘の回答をでっち上げてしまうトラブルのことですね。
もっともらしい嘘が招く重大なトラブル
ナレッジの検索精度が低く、社員の質問に対する適切な情報を自社データの中から見つけられなかった場合、AIは「わかりません」と素直に言わず、自身の事前学習データ(世の中の一般的な知識)だけでなんとか回答を作ろうと無理をしてしまいます。
例えば、「出張旅費の日当はいくらですか?」と聞かれたときに、自社の規定(例:1日3,000円)がうまく検索に引っかからず、世間一般的な相場や他社の事例を引っ張ってきて「日当は5,000円です」と答えてしまうケースです。
これを信じた社員が間違った精算をしてしまい、経理部門との間で大きなトラブルに発展する……なんてことは絶対に避けなければなりません。
業務で使う以上、このような不正確な情報は致命的であり、ハルシネーションを放置することは、会社の業務プロセスに大きな混乱を招く恐怖の種になりかねません。
回答品質を左右するインデックス設定
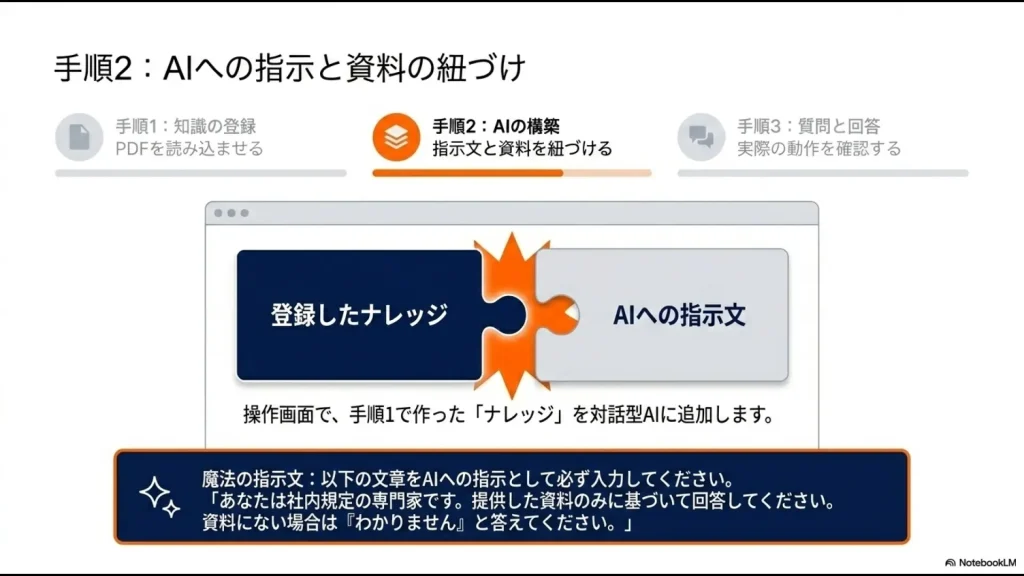
こうした恐ろしいハルシネーションを防ぎ、AIが自社データの中から的確に答えを見つけ出すために欠かせないのが「インデックス設定」です。
アップロードしたテキストデータを、AIが検索しやすい「ベクトル(数字の羅列)」に変換するプロセスのことですね。ここを理解して設定できるかどうかが、RAG構築の腕の見せ所です。
ハイブリッド検索で「言葉の揺らぎ」を吸収する
Difyでは、高品質なベクトル検索(意味ベースの検索)と、従来のキーワード検索(完全一致検索)を組み合わせた「ハイブリッド検索」を利用することができます。
現場のユーザーが入力する質問は、私たちが想定しているほど綺麗ではありません。
「パソコントラブル」と検索する人もいれば、「PC 壊れた」「画面 真っ暗」と検索する人もいます。こうした言葉の揺らぎや言葉足らずな質問にどう対応するかが課題になります。
ハイブリッド検索を使えば、「文脈としての意味」と「ドンピシャのキーワード」の両面から関連する情報を探し出すため、検索のヒット率が格段に向上します。
さらに、検索結果のスコア閾値(しきいち)を調整することで、関連性の低い無駄な情報をAIに渡さないようにするフィルター機能も極めて重要です。
「関連度が70%以上の確実な情報だけをAIに渡し、それ以下なら『該当する規定が見つかりません』と答えさせる」といった制御が可能になります。
ここを丁寧にチューニングするかどうかで、最終的な回答品質は天と地ほど変わってくるのです。
元情シスが語るAI導入のよくある失敗
私自身、過去の情シス時代に社内システムの導入で何度も苦い経験をしてきました。
「最新のSaaSツールを入れれば、魔法のように業務が効率化して、みんな喜んでくれるはずだ」という幻想を抱き、事前の十分な検証や運用設計を怠って現場に丸投げした結果、誰にも定着せずにフェードアウトしていったシステムがいくつもありました。
Difyでのナレッジ構築も、本質的には全く同じです。
運用フェーズを見据えない導入は必ず頓挫する
一番やってはいけない失敗は、「技術的な仕様やAIの癖を理解せずに、見よう見まねでとりあえず動くものを作って満足してしまうこと」です。
チャットボットが応答した瞬間に達成感を感じてしまい、その後のメンテナンスについて考えていないケースですね。
社内の規定は毎年のように変わります。データの鮮度管理はどうするのか、古い規定が検索されないようにするにはどうメタデータを設定すればいいのか。
そうした運用フェーズの設計を後回しにすると、結局は「ファイルを手動で削除してアップロードし直す」という手作業でのメンテナンス地獄に陥り、担当者が疲弊してしまいます。
AI導入は、ツールを導入した日がゴールではありません。継続的に精度を磨き上げ、データ鮮度を保ち、現場の信頼を勝ち取って初めて成功と言えるのです。
失敗しないDifyのナレッジの使い方
ここまで、ただデータを入れるだけのリスクや、現場に浸透しない理由についてお話ししてきました。
では、実務で本当に役立つ、精度の高いRAGシステムを構築するには具体的にどう設定すればよいのでしょうか。
ここからは、ハルシネーションを力強く抑え込み、的確な回答を引き出すための実践的かつ技術的なアプローチについて解説していきますね。
精度を劇的に上げるチャンク分割のコツ
Difyでナレッジを構築する際、多くの方が最初につまずき、かつ回答精度を決定づける最重要のプロセスとなるのが「チャンク分割」です。
チャンクとは、アップロードしたマニュアルや社内規定などの長大なドキュメントを、AIが扱いやすいように数十〜数百文字程度の小さなテキストの塊に切り分ける作業のことですね。
実は、この分割のアプローチ一つで、AIの理解度は劇的に変わります。
文脈を維持する「親子分割モード」の威力
デフォルトの汎用的な分割モードのまま、最大文字数などで機械的にブツ切りにしてしまうと、文章の文脈や意味のつながりが完全に失われてしまいます。
例えば、「交通費精算について」という大見出しの下に箇条書きでルールが書かれている場合、分割されたチャンクの中に「交通費」というキーワードが含まれていなければ、AIはそれが何についてのルールなのか判断できなくなってしまいます。
そこでおすすめしたいのが、親子分割(Parent-Child Chunking)という高度な設定手法です。
これは、全体の文脈を保持する大きなテキストブロック(親チャンク)と、具体的なキーワード検索に引っかかりやすくするための細かなテキストブロック(子チャンク)の階層構造に分けてデータを管理する方法です。
子チャンクでユーザーの質問に合致する細かなキーワードを素早くヒットさせつつ、AIの脳内には親チャンクが持つ広い文脈をコンテキストとしてドカッと渡すことで、「細かい部分も拾いつつ、全体像も見失わない」という極めて精度の高い回答生成が可能になります。
社内の複雑な規定や手順書を読み込ませる場合は、ぜひこの親子分割モードを意識して設定してみてください。これだけで現場からの不満はかなり減るはずですよ。
運用前の検索テストで回答品質を担保
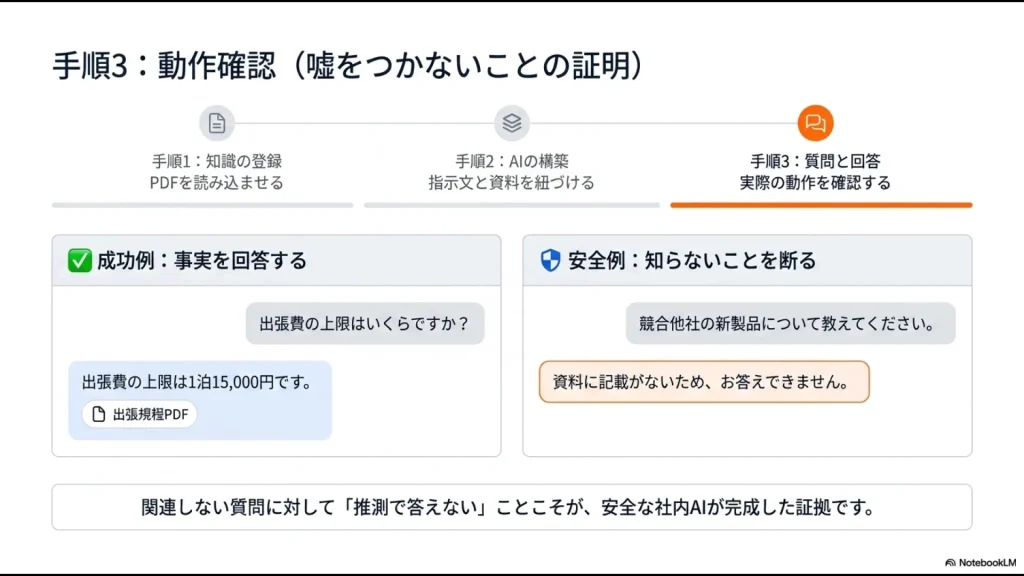
チャンク分割やインデックスの設定が終わったら、「よし、これで完璧だ!」とすぐに全社へ公開したくなる気持ちは痛いほどわかります。
私も新しいシステムができると、早くみんなに見せたくてウズウズしていました。しかし、Difyのナレッジ構築において、運用前の「検索テスト」をスキップすることは、時限爆弾を抱えたまま船出するようなものです。
テストなきリリースは炎上のもと
Difyのナレッジ設定画面には、「ヒットテスト(検索テスト)」という非常に便利な機能が備わっています。
これは、設定したナレッジに対して実際にクエリ(質問)を投げ、どのテキストチャンクがどんなスコアでヒットしているかを事前に確認できるシミュレーション機能です。
ここで、実際に現場の社員が入力しそうな「曖昧な質問」や「社内特有の略語を使った質問」を何度も打ち込んでみることが極めて重要です。
事前のテスト段階で意図した社内ドキュメントが上位にヒットしていない場合、本番のチャットボット環境では確実にハルシネーション(嘘の回答)を引き起こします。
もし検索結果がズレている場合は、ハイブリッド検索の「意味優先・キーワード優先」の重み付けスライダーを微調整したり、ノイズを省くためのスコア閾値を見直したり、場合によっては元のPDFドキュメントの表現自体を少しAI向けに修正する必要が出てきます。
この地道な検索テストとチューニング作業こそが、実務で使い物になるAIと、ただのおもちゃで終わるAIの決定的な差を生み出します。品質管理プロセスとして、絶対に省いてはいけない工程ですね。
担当者の我流設定が引き起こす属人化
AIの導入が初期のテスト段階を過ぎて本格的な運用フェーズに入ると、次に見えてくる大きな壁が「属人化」のリスクです。
特に、ITリテラシーの高い管理部門の担当者や情シス担当者が、一人で張り切ってDifyのナレッジ構築を進めてしまった場合、この問題は後々非常に厄介なことになります。
属人化を防ぐための運用ルール策定
ネット上の断片的なブログ記事やSNSの情報を拾い読みして、見よう見まねで複雑なパラメータをいじったり、独自のルールでメタデータ(ドキュメントの更新日やバージョンなどの属性情報)を付与したりしていると、「なぜその設定値にしたのか」「どういう意図でチャンクサイズを決めたのか」が、構築した担当者本人にしかわからない完全なブラックボックスが完成してしまいます。
もしそのエース担当者が異動や退職をしてしまったら、誰も新しいマニュアルの追加やエラーの修正ができなくなり、システム全体が完全に腐敗してしまうでしょう。
この事態を防ぐためには、Difyのアーキテクチャや機能の正しい仕様を根本から理解し、組織として統一された運用ルールを策定することが不可欠です。
「新しい就業規則を追加する際のファイル命名規則」や「古いドキュメントを削除する際のAPI連携の仕組み」などを事前に明文化し、誰が担当になっても同じ品質でAIを維持・管理できる体制を作っておくことが、持続可能なAI運用の鍵になります。
体系的な学習で最短ルートのRAG構築
ここまで、チャンク分割の重要性やハイブリッド検索のテスト、属人化のリスクなど、かなり踏み込んだ実務的な内容をお話ししてきました。
「なんだか覚えることが多くて難しそうだな」「自分たちだけの知識で最後まで設定しきれるだろうか」と不安に感じた方もいらっしゃるかもしれませんね。
実際、Difyは非常に多機能で強力なツールですが、高度なエンタープライズ向けのRAGシステムを我流の知識だけで構築しようとすると、必ずどこかで精度の壁にぶつかり、設定の沼にハマってしまいます。
断片的な知識から体系的な理解へ
無駄なトライアンドエラーに膨大な時間を費やし、現場からのクレーム対応に疲弊する前に、実績のある専門家から体系的な知識をインプットすることを強く推奨します。
私自身、最初はネット上の無料記事を繋ぎ合わせて試行錯誤し、多くの時間を溶かしてしまいました。
しかし、Udemyなどの優良な動画講座でプロの設計を体系的に学んだことで、エラーの沼から抜け出し、たった数日で実務レベルのRAGを構築・運用できるようになりました。
結果的にそれが、圧倒的な業務効率化への「最短ルート」になります。
💡 AIツールの学習、どの講座から始めればいいか迷っていませんか?
「Difyを本格的に学びたいけれど、たくさんある講座の中でどれが本当に実務で役立つのか分からない…」という方向けに、元情シスの私が自腹で受講して厳選したおすすめ講座を以下の記事でまとめています。
無駄な買い物をしたくない方は、ぜひ参考にしてくださいね。
Difyのナレッジの使い方を動画で学ぶ
体系的にDifyのナレッジの使い方をマスターし、現場の社員から「これ、めちゃくちゃ便利ですね!」と感謝されるようなAIボットを作りたい方には、動画で学ぶのが一番かなと思います。
実際のDifyの管理画面を操作しながら、どこをクリックしてどのようなパラメータを設定すれば良いのかを視覚的に追体験できるため、書籍や文章に比べて圧倒的に学習効率が高くなります。
視覚的な学習がもたらす圧倒的な理解度
文字だけではどうしても伝わりにくい「検索テストでスライダーを動かした際のヒット結果の変化」や「親子チャンクの効果的な切り方のニュアンス」なども、プロの講師のデモンストレーションを見ることでスッと腹落ちするはずです。
私自身、情シスとして新しいITツールを社内に導入する際は、まずこうした動画教材で全体像をしっかりと把握してから、自社の実務要件に落とし込むようにしています。
なお、Udemyの講座価格は頻繁に行われるセールなどの時期によって大きく変動する可能性があります。
具体的な講座のカリキュラム内容や最新の価格については、正確な情報を必ずご自身で公式サイトにて直接ご確認くださいね。
チャンク分割の最適化やハルシネーション対策など、独学ではつまずきやすいDifyの本格的な設定手順を、プロの画面を見ながら一緒に手を動かして学べます。
セール期間中なら書籍1冊分の価格で、一生モノのDXスキルが手に入りますよ。
\ 現場で使えるRAG構築を最短でマスター! /
社内の機密データを扱うシステムの導入にあたっては、最終的な判断は自社のセキュリティ要件に照らし合わせ、専門家やIT部門としっかり協議した上で進めてください。
正しい知識をしっかりと身につけて、無駄な回り道をせずに、ぜひ御社にも「最高に頼れるAIアシスタント」を誕生させてくださいね!




