SkillStack Lab 運営者の「スタック」です。
最近、Google Labsが提供しているNotebookLMを仕事やリサーチで使い始めたのですが、資料をアップロードした瞬間に文字が記号だらけになって困った経験はありませんか。
特に日本語のドキュメントを読み込ませる際、Notebooklmで文字化けが発生してしまうと、AIによる分析や要約といった便利な機能がすべて台無しになってしまいますよね。
PDF 読み込めないといったトラブルや、日本語設定が反映されずに回答が英語になってしまうなど、日本語環境特有の壁を感じている方も多いはずです。
この記事では、私が実際にツールを使い倒す中で見つけた、文字化けや音声の日本語化、そして精度の低い回答(ハルシネーション)の原因となるデータの不備を防ぐための具体的な解決策を詳しく解説します。
この記事を読めば、あなたのNotebookLMもスムーズに使いこなせるようになるはずですよ。

- 文字化けを即座に解消するためのNotebookLM内部の設定手順
- 画像PDFや古い文字コードが原因で読み込めない時の変換テクニック
- 音声オーバービューを日本語で出力させるための正しい設定方法
- データの不備が招く嘘やハルシネーションを最小限に抑える方法
NotebookLMの文字化けを解消する基本の設定
NotebookLMは非常に強力なAIツールですが、多言語に対応しているがゆえに、ちょっとした設定の食い違いで表示がおかしくなることがあります。
まずは、高度な修正を試みる前に確認しておきたい基本の設定から見ていきましょう。
PDFの読み込みに失敗する要因と解決策
資料を読み込ませたときに「□□□」や意味不明な記号が表示される場合、その多くはPDF内部の「文字エンコーディング」に問題があります。
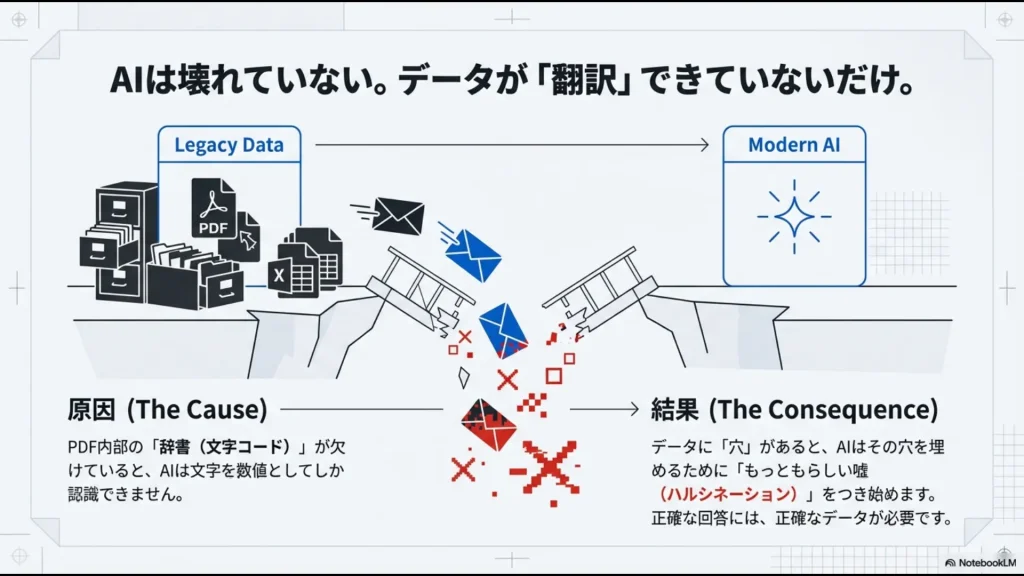
私たちが画面で見ている文字は、データ上では特定の数値に変換されています。この数値を文字に戻すための「辞書(CMapやToUnicode)」がPDFに含まれていないか、壊れていると、AIはそれを正しく読み取ることができません。
特に、古い複合機でスキャンした資料や、海外製の一部のPDF作成ソフトで書き出したファイルは、日本語特有の文字コード(Shift_JISなど)が混在し、NotebookLMが採用している最新のUTF-8エンコーディングと衝突して「技術的摩擦」を起こしやすいです。
自分のPDFが「生きている」か確認する方法
まず試してほしいのが、PDFビューアー(ChromeやAdobe Acrobatなど)でそのファイルを開き、マウスのドラッグで文字を1文字ずつ正確に選択できるかどうかです。
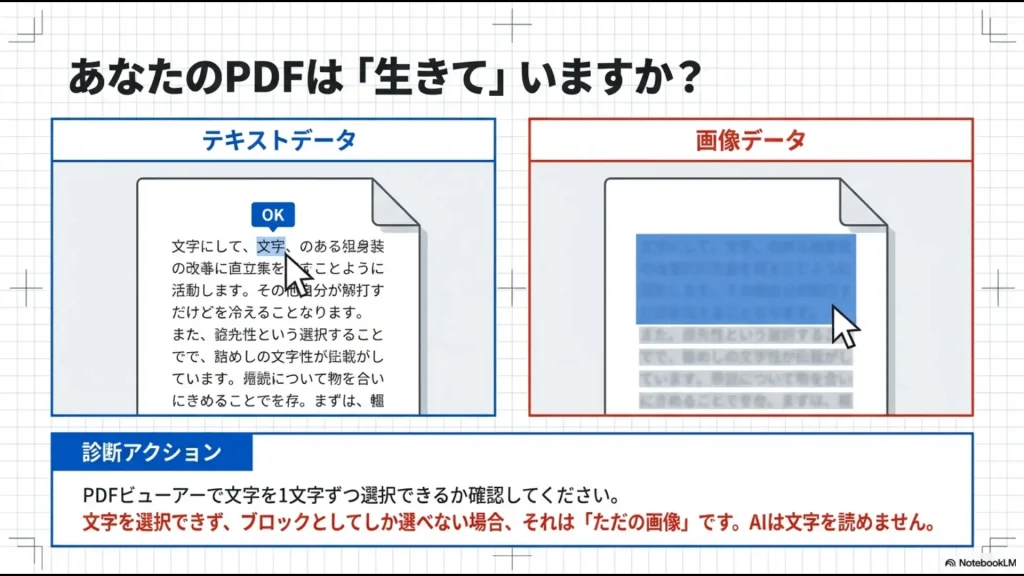
もし1文字単位で選択できず、四角いブロックとしてしか選択できない場合は、それはテキストデータを持たない「画像としてのPDF」です。
この状態では、NotebookLMのテキスト抽出機能が正常に働かず、文字化けが発生する可能性が非常に高くなります。
画像化されたPDFをAIに正しく認識させる方法
前述の「画像としてしか認識されないPDF」を無理やりNotebookLMに読ませると、AIはノイズだらけのデータを無理に解析しようとし、結果的に意味不明な回答を生成してしまいます。
これを防ぐには、事前に「テキストレイヤー」を付与する作業が必要です。
最も手軽で強力な解決策は、GoogleドライブのOCR(光学文字認識)機能をブリッジとして使うことです。
- 対象のPDFをGoogleドライブにアップロードする
- ファイルを右クリックして「アプリで開く」>「Googleドキュメント」を選択する
- 生成されたGoogleドキュメントの中身を確認し、文字化けが解消されているか見る
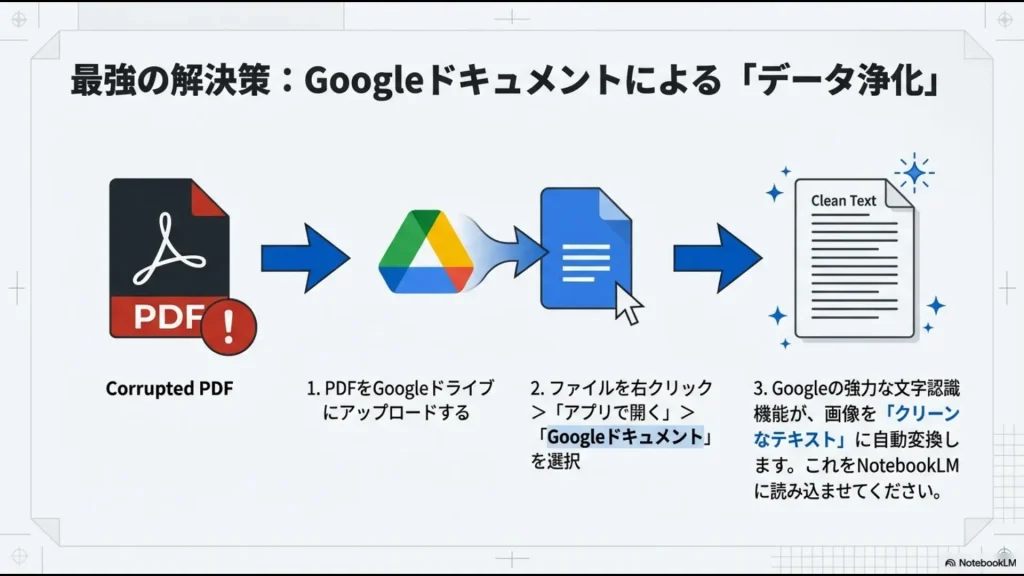
Googleのサーバーサイドで動作するOCRは非常に優秀で、画像の中にある文字を高精度でテキストデータ化してくれます。
この「浄化された」GoogleドキュメントをNotebookLMのソースとして追加すれば、文字化けの悩みはほぼ一掃されますね。
日本語設定で出力言語を確実に変更する手順
資料の内容は正しく読み取れているのに、AIからの回答がなぜか英語になってしまうことがあります。
これも広い意味での「言語の化け」ですよね。NotebookLMは現在、日本語を含む80以上の言語に対応していますが、デフォルトの自動判定(Auto)に頼りすぎると、英語で回答されることがたまにあります。
画面右上の設定メニュー(歯車アイコンなど)を開き、「Settings」>「Output Language」から「Japanese(日本語)」を明示的に選択しましょう。
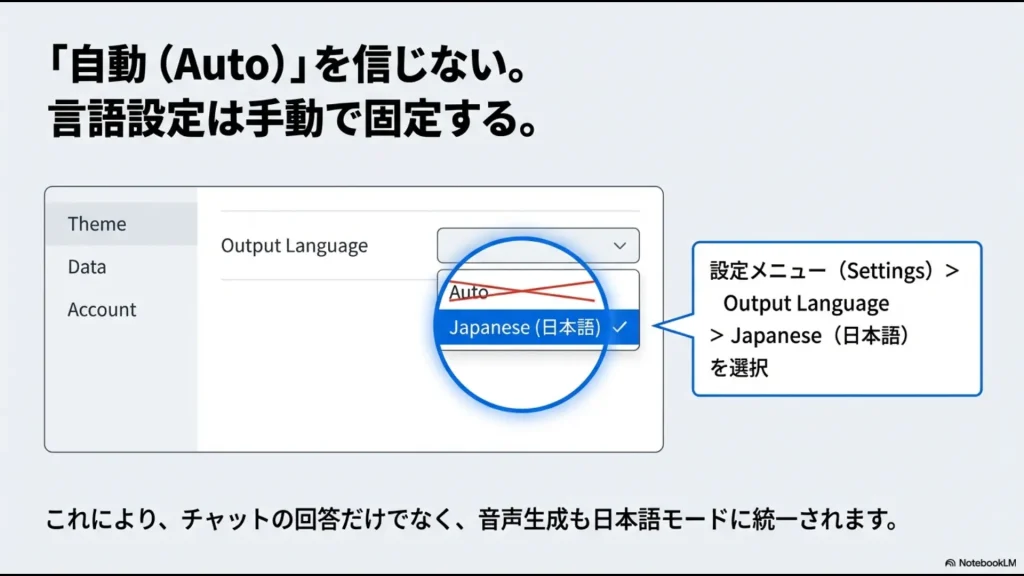
この設定を固定しておくことで、チャットの回答だけでなく、後述する音声オーバービューの生成言語も日本語に統一されやすくなります。
Googleの公式発表によると、Gemini 1.5 Proを基盤とするNotebookLMは多言語対応が大幅に強化されており、正しく設定すれば非常に自然な日本語を扱えます(参照:Google公式ブログ「NotebookLM goes global with Gemini 1.5 Pro」)。
日本語の使い方をマスターして要約精度を高める
AIに対する指示(プロンプト)の書き方一つで、文字化けの影響を最小限に抑えることも可能です。
例えば、ソースの一部がわずかに文字化けしていても、AIはその前後の文脈から内容を推測する力を持っています。
「この資料を日本語で要約してください。特に専門用語の解説を重点的にお願いします」というように、「日本語で」という指示をプロンプトに明記することが意外と重要です。
これにより、AIが「このタスクは日本語で行うべきだ」と強く認識し、出力の安定性が増すかなと思います。
音声が日本語にならない場合の言語設定確認
2025年以降、NotebookLMの目玉機能となっている「音声オーバービュー」。
2人のAIホストが資料を元に対談してくれる機能ですが、ここでも「音声の文字化け(英語で喋る)」が起きがちです。
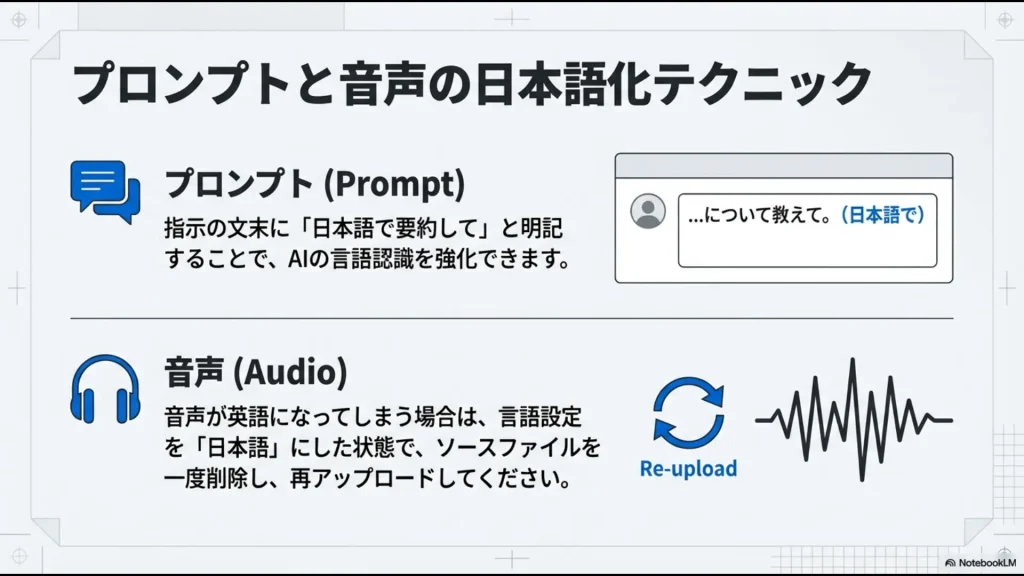
もし設定で「日本語」を選んでいるのに英語で喋る場合は、一度ソースファイルを削除してアップロードし直してみてください。
設定を変更した後にファイルを再認識させることで、音声生成エンジン側にも「日本語モード」が正しく伝わることが多いです。
最新のAI音声合成技術(MeloTTSなど)のおかげで、一度日本語モードが定着すれば、驚くほど滑らかな日本語対話を生成してくれますよ。
NotebookLMの文字化けを防ぐソース修正術

設定をいじっても直らない頑固な文字化けは、ソースファイル自体の「構造」を修正する必要があります。
ここでは、プロフェッショナルな視点からデータを整える方法を紹介します。
GoogleドキュメントのOCRで文字を抽出する
先ほども少し触れましたが、Googleドキュメントを介した変換は「最強の浄化術」です。
PDFは本来「印刷するための形式」であって「データを再利用するための形式」ではないため、AIとは相性が悪い部分があるんですよね。
| 元のファイル形式 | 推奨される変換手順 | 期待できる効果 |
|---|---|---|
| スキャンPDF | Googleドライブで「Googleドキュメント」として開く | 画像内のテキストが100%検索・抽出可能になる |
| 古いWord/Excel | Googleスプレッドシート/ドキュメントに一度変換して保存 | 文字コード(Shift_JIS)がUTF-8に統一される |
| WebサイトのURL | 内容をコピーしてテキストファイル(.txt)として保存 | 不要な広告やJavaScriptの干渉を排除できる |
このように、NotebookLMが最も理解しやすい「クリーンなテキストデータ」を供給することが、RAG(検索拡張生成)の精度を最大化するコツです。
私も大量の論文やマニュアルを読み込ませる際は、必ずこの手順でデータを整えるようにしています。
Excelの文字コードによるエラーを回避するコツ
Excelファイル(.xlsx)の読み込みは便利ですが、ここには「Shift_JISの亡霊」が潜んでいます。
日本のビジネス現場では、いまだに古い文字コードで作成されたデータがやり取りされることがあります。これをそのままNotebookLMに投げると、見事に文字化けが発生します。
対策として、Excelファイルを一度「Googleスプレッドシート」として開き直し、そこから再度エクスポートするか、直接ドライブ経由で読み込ませる方法が安全です。
また、Pythonなどで自動生成したCSVデータなども、保存時に「UTF-8 (BOMなし)」を指定しているか確認することをおすすめします。データの「衛生管理」が、AIのパフォーマンスを左右するわけですね。
読み込めないファイルの制限とセキュリティ解除
「文字化け以前に、ファイルが追加できない!」というときは、ファイルのセキュリティ設定を疑ってみてください。
特に企業から提供された資料や、政府機関の公文書PDFには、強力なコピー防止制限がかかっていることがあります。
パスワードがかかっているPDFや、印刷・コピーが制限されているPDFは、AIのクローラーが中身を読み取ることができません。
その結果、中身が「空」として扱われたり、断片的なゴミデータだけが読み取られて文字化けのような挙動を示したりします。
セキュリティ解除が必要な場合は、適切な権限を確認した上で、PDFの再保存(仮想プリンターで「PDFとして印刷」など)を行うと、プロテクトが外れて読み込めるようになる場合があります。
ただし、著作権や機密保持にはくれぐれも注意してくださいね。
嘘やハルシネーションを招く文字化けの修正
AIがもっともらしい嘘をつく「ハルシネーション」の大きな要因の一つが、実はこの文字化けです。AIは、読み取ったデータに「穴」があると、その穴を自分の知識で埋めようとします。
もしソースが記号だらけだと、AIはそれを「未知の言語」か「高度に暗号化された情報」と勘違いし、想像力豊かに嘘を作り上げてしまうんです。
ソースの確認を怠らない
NotebookLMの回答に疑問を感じたら、必ず「引用元(ソース)」のアイコンをクリックして、AIが実際にどのテキストを参照したか確認しましょう。
そこで文字が化けていれば、AIの回答を疑うべきサインです。「綺麗なデータを食べさせれば、正確な答えが返ってくる」というシンプルな原則を忘れないようにしたいですね。
ブラウザ起因で読み込みに失敗する際の対処法
意外と盲点なのが、ブラウザの拡張機能です。
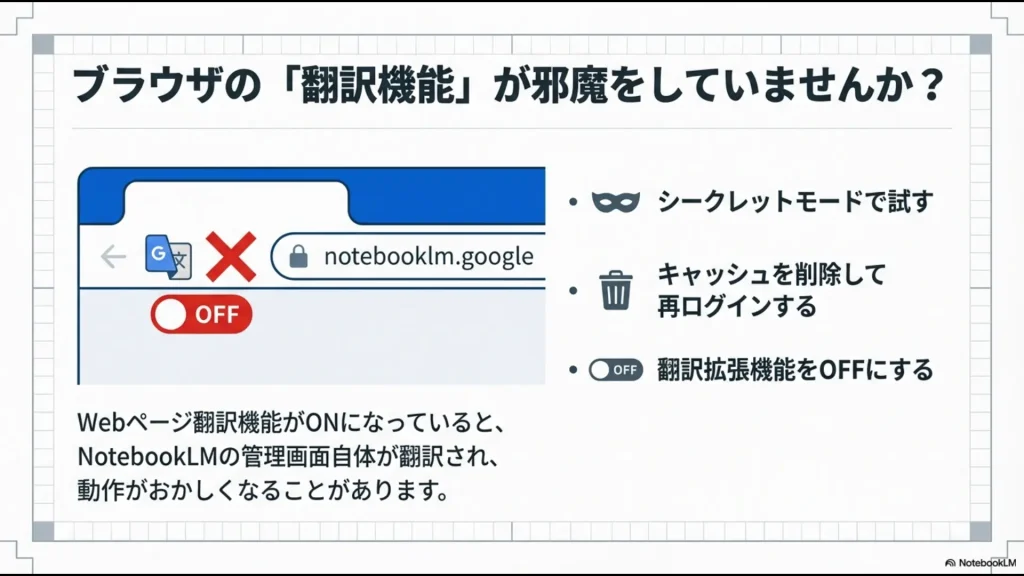
特に「Webページを丸ごと翻訳する」系の拡張機能がオンになっていると、NotebookLMの管理画面自体が翻訳対象になり、JavaScriptの動作を阻害して文字化けや読み込みエラーを引き起こすことがあります。
もし原因が分からないトラブルに遭遇したら、以下の3ステップを試してみてください。
- ブラウザのシークレットモードで試す(拡張機能の影響を排除)
- キャッシュとクッキーを削除して再ログインする
- 別のブラウザ(Chrome、Edgeなど)で動作を確認する
特にモバイルアプリ版で文字化けが起きる場合は、PC版で一度ファイルをセットアップしてから同期させるという「回避ルート」も有効ですよ。
💡 独学でのAI活用に限界を感じていませんか?
AIツールでのドキュメント処理は非常に便利ですが、実務で頻発する「文字化けの解消」や「フォーマットの修正」といったイレギュラーなエラー対応を独学で試行錯誤するのは、実はかなりの時間と労力(コスト)がかかります。
「もっと体系的にAIを学んで、一気に業務を効率化したい」
「ネットの断片的な情報ではなく、実務に直結する『型』が欲しい」
そう感じたことのあるバックオフィス担当者に向けて、元社内SE・現役管理職の視点で「失敗しない生成AIスクール」を厳選比較しました。
時間を無駄にせず、最短でDX人材を目指したい方は、ぜひ無料相談を活用してプロに壁打ちしてみてください。
\独学の試行錯誤を今日で終わらせるなら/
NotebookLMの文字化け対策に関するまとめ

ここまで、NotebookLMの文字化けを解消するためのさまざまなテクニックをご紹介してきました。
文字化けはAIの能力不足ではなく、多くの場合、私たちの手元にある「レガシーなデータ構造」と「最新のAI技術」の間に生まれた隙間のようなものです。
「出力言語を日本語に明示する」「GoogleドキュメントのOCRでデータを浄化する」「ファイル形式を最新のUTF-8に整える」といった、ほんの少しの工夫で、NotebookLMはあなたの強力な知能パートナーになってくれます。
この記事で紹介した解決策を一つずつ試して、ぜひ快適なAIライフを手に入れてください。
もちろん、AIの回答を盲信せず、重要な情報は公式サイトや専門家の判断を仰ぐことも忘れずに。SkillStack Labでは、これからもこうした「明日から使えるデジタルスキル」をシェアしていきます。
一緒に楽しみながらスキルを積み上げていきましょう!