
SkillStack Lab 運営者の「スタック」です。
日々の業務で飛び交う膨大なメッセージの中から、重要な情報を見つけ出すのに苦労していませんか。特にNotebookLMとSlackの連携について興味を持ち、この記事にたどり着いた方は多いかもしれませんね。
プロジェクトの経緯や仕様の変更など、大切な議論がタイムラインに流れてしまい、あとから検索してもなかなか見つからないという悩みは、多くの現場で共通しています。
NotebookLMをSlackと連携させて要約を自動化する使い方や、ZapierやAPIを活用した具体的な仕組みの構築方法について、気になっている方も多いのではないでしょうか。
元情シスとしての経験も踏まえながら、私が実際に現場で試行錯誤して見つけた、効果的な情報整理のアプローチをお伝えします。
この記事を読むことで、散在するメッセージを価値あるナレッジベースへと変えるヒントが見つかるはずです。
- Slackに埋もれがちな情報をNotebookLMで整理する具体的な仕組み
- ノーコードツールZapierを使った連携設定のポイント
- APIを利用した高度なBot開発と運用の裏側
- 現場でのエラー回避策やセキュリティに関する実践的な知識

元情シスのNotebookLMやSlackに関する連携術
ここでは、私が情シス時代に培った視点も交えながら、NotebookLMやSlackを連携させる具体的な手法について解説していきます。
リアルタイムなやり取りが便利な反面、重要な情報があっという間に流れてしまうという課題をどう解決するか。実際の構築手順や運用フェーズでの注意点などを、順を追って見ていきましょう。
私が実践した連携と自動化の基本
日々のコミュニケーションにおいて、チャットツールは手放せない存在ですよね。
しかし、その手軽さゆえに、意思決定のプロセスや顧客からの貴重なフィードバックが、雑談の中に埋もれてしまうことが多々あります。
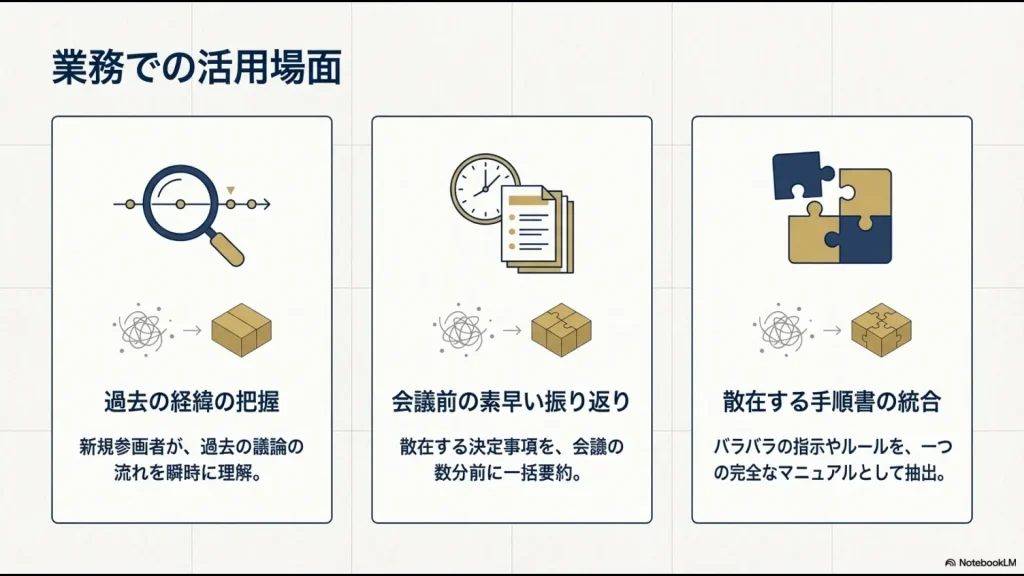
新しくプロジェクトに参加したメンバーが、過去の経緯を把握するために過去ログを延々とスクロールする姿を、私も何度も目にしてきました。
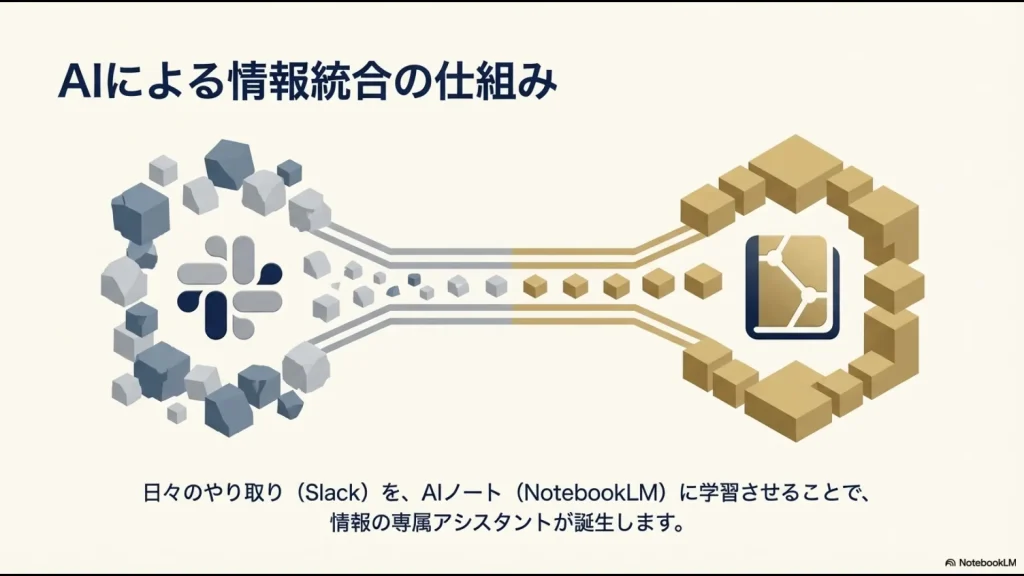
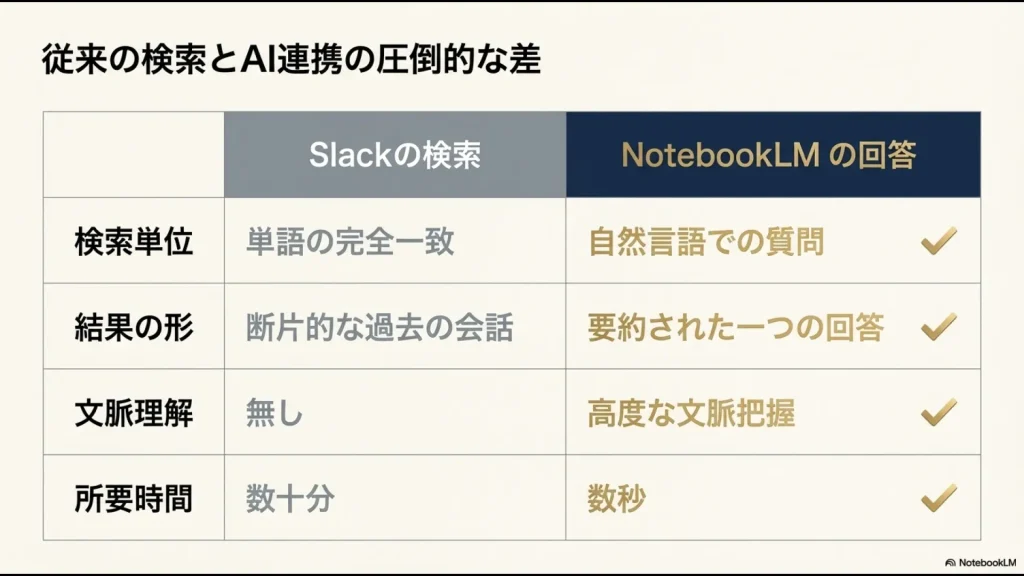
この「情報のサイロ化」と「コンテキストの喪失」を防ぐための強力な武器となるのが、AIを活用したナレッジマネジメントです。
特に、与えられたドキュメントに厳密に従って回答を生成するNotebookLMは、事実ベースでの情報抽出において非常に優秀かなと思います。
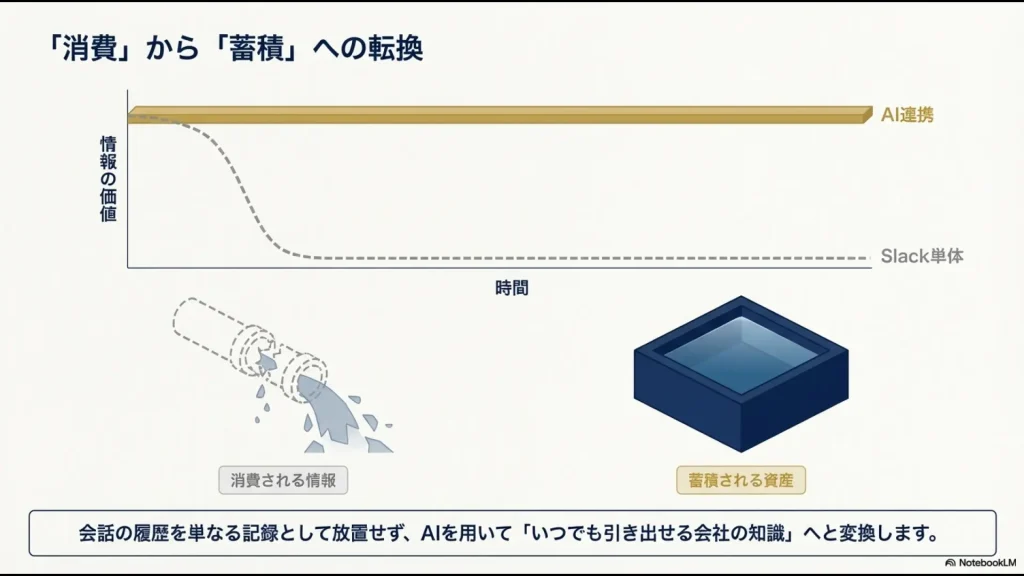
連携のためのアーキテクチャ設計
現状、両者を直接つなぐネイティブなプラグインは提供されていません。
そのため、データの中継地点(バッファ)としてGoogleドキュメントやスプレッドシートなどを介在させるアーキテクチャを採用するのが基本になります。
生のデータを直接AIに放り込むのではなく、一度ドキュメントという「受け皿」を用意することで、ノイズの除去やメタデータの付与が可能になります。
これが、後々の検索精度を劇的に向上させるポイントですね。
Zapierを用いた使い方のコツ
エンジニアリングのリソースが限られている場合や、まずは素早くプロトタイプを作りたい場合に重宝するのが、ノーコードツールのZapierです。
特定のチャンネルへの投稿をトリガーにして、指定したGoogleドキュメントに自動でテキストを追記していくシンプルな仕組みを作ることができます。
設定画面のUIも分かりやすいので、非エンジニアの方でも比較的簡単に構築できるはずです。
フィルタリングとメタデータの付与が鍵
設定自体は直感的に行えますが、運用を成功させるためにはちょっとしたコツがあります。
すべてのメッセージを無差別に抽出するのではなく、特定のハッシュタグ(例えば #nlm など)が含まれる発言だけを拾うようにフィルタリングするのがおすすめです。
重要な議論のまとめに対してだけハッシュタグをつける運用にすれば、AIの処理負荷も減らせます。
また、単に本文だけを転記するのではなく、「誰が」「いつ」「どのチャンネルで」発言したのかというメタデータ(送信者名やタイムスタンプ)を必ずセットにして追記するようにしましょう。
誰の発言か分からない言葉の羅列は、AIにとっても意味不明なノイズになってしまうからです。
APIを使ったBot開発の裏側
社内に開発リソースがあり、より高度な業務要件を満たしたい場合は、公式APIを活用したカスタムBotの開発が視野に入ってきます。
私自身、この双方向インテグレーションの構築にはかなりやりがいを感じました。
Slackアプリの開発者コンソールからBotを作成し、適切な権限(スコープ)を付与することで、より柔軟なデータのやり取りが可能になります。
複雑な要件を満たす双方向インテグレーション
例えば、チャット上で特定のコマンドを打つと、Botが対象スレッドの会話履歴を一括取得し、バックエンドのプログラム経由でAIに要約させ、その結果を元のスレッドにリプライで返してくれる、といった仕組みです。
これにより、メンバーは使い慣れた画面から離れることなく、瞬時にナレッジを引き出せるようになります。
| 連携アプローチ | 実装難易度 | リアルタイム性と同期方式 | 推奨ユースケースと利点 |
|---|---|---|---|
| Zapier連携 | 低〜中 | 高(逐次追記) | 特定チャンネルの監視、非エンジニアによる迅速な構築 |
| カスタムBot | 高(サーバーサイド開発必須) | 高(Webhookによる完全同期) | 複雑なルーティング、AI回答の自動返信 |
| 手動エクスポート | 低 | 低(バッチ処理) | 過去ログの一括解析、単発の高度なリサーチ |
悩まされた読み込みエラーの回避策
システムを稼働させ始めてから一番悩まされたのが、大量のデータをアップロードした際のエラーやタイムアウトです。
数年分に及ぶチャンネルの履歴を一度に投入しようとすると、上限となる文字数やファイルサイズをオーバーしてしまい、ベクトル化の処理が途中で止まってしまいます。
アップロードが完了しないからといって何度も更新ボタンを押すと、最悪の場合はレートリミット(アクセス制限)に引っかかる恐れもあります。
データを分割してシステム負担を減らす
こうした事態を回避するための最も確実な方法は、事前のファイル分割です。
全ログを1つの巨大なファイルにまとめるのではなく、四半期ごとやプロジェクトフェーズごとに論理的に分割し、個別のソースとして登録していくのが安全ですね。
NotebookLMは複数のソースを同時に読み込める特性があるので、小分けにしてアップロードしても全体の分析には支障が出ません。
※この記事で紹介しているAPIの仕様やシステムの上限値(ファイルサイズや文字数など)は、あくまで執筆時点の一般的な目安です。
大幅な仕様変更によって制限が緩和・変更される可能性があるため、正確な最新情報は必ず公式サイトのドキュメント等をご確認ください。
信頼できるセキュリティの検証結果
企業の機密情報や未公開のプロジェクト内容、人事関連の決定事項が含まれるデータを外部システムに渡すにあたり、管理部門長として最も神経を使ったのがセキュリティとデータガバナンスです。
どれだけ便利なツールでも、情報漏洩のリスクがあれば現場には導入できません。
管理コンソールでの権限制御とデータ保護
無料のコンシューマー向けAIサービスに機密データを入力するリスクが懸念される中、Workspace環境のコアサービスとして提供されるNotebookLMであれば、アップロードしたデータやプロンプトが他社のモデル学習(再学習)に二次利用されることはないという明確なポリシーが適用されています。
これなら企業としても導入のハードルが下がります。
さらに、管理コンソール経由で組織部門(OU)単位でのアクセス権限を細かく制御できるため、特定の部門のみにフルアクセスを許可するといった、コンプライアンス要件に合わせたデプロイメントが実現できるのは大きな安心材料ですね。
NotebookLMとSlackを活用した現場運用のリアル
技術的な連携基盤が整っても、それを実際の業務プロセスにどう組み込み、現場のメンバーに定着させていくかが本当の勝負です。ここからは、実運用フェーズで直面した生々しい課題と、私なりの解決アプローチについてさらに深掘りしていきます。
苦労したJSONデータの前処理
過去の全社ログをエクスポートして一括分析しようとした際、そのデータ形式は構造化されたJSONフォーマットになります。
AI側である程度よしなにパースしてテキストとして解釈してくれるとはいえ、そのまま丸ごと突っ込む運用はあまりおすすめしません。
本当に必要な意思決定だけを抽出する
なぜなら、JSONデータの中にはシステムメッセージ(「〇〇さんがチャンネルに参加しました」など)や、絵文字のショートコード(:smile:など)、過度な改行、単なる挨拶のやり取りなどが大量に含まれているからです。
そのまま読み込ませると、本当に重要な意思決定のシグナルが、不要なノイズの海に埋もれてしまうリスクがあります。
読み込み前に簡単なPythonスクリプト等でこれらを整理し、意味のある会話ブロックごとに構造化しておくことが、高精度な要約結果を得るための重要なコツだと痛感しました。
Notionとの比較と使い分け
社内のナレッジ管理といえば、Notionをメインで使っている方も多いのではないでしょうか。
実際、Notion AIも非常に強力な機能を備えており、プロジェクト管理には欠かせない存在です。
ここで大事なのは、NotebookLMとNotionのどちらか一方を選ぶという「競合」の視点ではなく、それぞれの設計思想の違いを理解して「使い分ける」ことです。
動的インサイトと静的データベースの融合
Notionは、ユーザーが能動的に情報を整理し「構造化」するためのプラットフォームです。
一方のNotebookLMは、手元にある雑然とした非構造化データに対して、AI自身が受動的に「解釈・分析・意味付け」を行うことに特化しています。
私のおすすめは、AIを使ってノイズだらけのチャットログから潜在的なリスクや決定事項を抽出し、その洗練されたクリーンな分析データを、マスターデータとしてNotionのページにインポート(保存)するという連携フローです。
一時的な洞察を、半永久的な資産に変えることができます。
代替ツールも検討すべきかの判断
「日々の情報を効率よくさばきたい」という最終的な目的から逆算すれば、必ずしも一つのツールに固執する必要はありません。
社内での利用環境やエンジニアリングスキル、予算に応じて、最適なツールを選ぶ視点を持つことも大切かなと思います。
コストと手軽さのトレードオフ
例えば、Slackが提供する公式のAI機能「Slack AI」は、複雑な設定なしにワンクリックで未読メッセージを要約してくれるなど、ユーザー体験としては圧倒的に優れています。
公式の発表によると、AIの活用でユーザーは1週間に平均97分もの業務時間を節約できると報告されています(出典:Slack公式『生産性向上と仕事でのコラボレーションを実現する AI ツール』)。
しかし、導入には高額なアドオン料金が必要になるというコストの壁があります。
また、機密性が極めて高く、自社サーバー内(ローカル環境)で全てを完結させたいという厳格な要件がある場合は、SurfSenseなどのオープンソースのRAG環境を構築するという選択肢も視野に入ってきますね。
自社の優先順位をしっかりと見極める必要があります。
現場で起きたハルシネーション対策
運用を始めてから現場のメンバーからよく相談されたのが、「AIに質問しても的外れな回答が返ってくる」、あるいは「情報がありませんと安全側に倒して回答を拒否される」という現象です。
チャット上のコミュニケーションは、暗黙の了解や過去の会議での口頭での決定事項など、ハイコンテクストな前提知識に基づいて進行することが多いため、テキスト化されたログだけではAIが文脈の裏側まで完全に理解できないのが原因です。
複数のドキュメントを組み合わせて補完する
この構造的な欠陥を補うために私が実践しているのが、マルチソース・グラウンディング手法です。
単純にチャットログだけを読み込ませるのではなく、そのプロジェクトの「企画書のPDF」や「要件定義書」、「社内特有の専門用語定義集」などを、別のソースファイルとして同時に読み込ませるのです。
関連資料を立体的に組み合わせることで、AIは断片的なやり取りと公式なドキュメントの記述を論理的に結びつけ、情報不足を補った精度の高いインサイトを導き出してくれるようになります。
1つのノートブックに複数のソースを登録できる強みを、最大限に活かすアプローチですね。
💡 AIでチャットを自動化した後は、「エクセル業務の自動化」も進めませんか?
NotebookLMとSlackの連携によって、コミュニケーション上の「情報迷子」や「ナレッジの属人化」は劇的に改善できます。
しかし、バックオフィス業務の根幹に、未だに「誰かが休むと回らないエクセルマクロ」や「手入力のコピペ転記作業」が残っていませんか?
せっかくAIで最先端の情報整理を構築しても、日々の定型業務が「気合いと根性のエクセル運用」のままでは、真の業務効率化(DX)は達成できません。
「関数やマクロのエラーに怯える日々から抜け出したい」
「誰かが休むと業務が回らない『エクセル属人化』を根本から解消したい」
そう感じたことのある総務・経理・バックオフィス担当者に向けて、元社内SE・現役管理職の視点で「日々の定型業務を劇的に楽にする脱エクセル(SaaS)ツール」を厳選しました。
いきなり会社で稟議を通す必要はありません。時間を無駄にせず業務を効率化したい方は、まずはノーリスクの無料登録や資料請求を活用して、専用ツールの圧倒的な「ラクさ」をご自身の目で確かめてみてください。
\ エクセルの手作業を今日でやめるなら /
総括するNotebookLMとSlackの未来

ここまで、ツールを連携させるためのアーキテクチャ設計から現場での運用ノウハウまで、幅広く解説してきました。
この連携は、単なるSaaS間のデータ転送にとどまらず、組織に埋もれていた暗黙知を検索可能な形式知へと変換する、非常に意義のある取り組みだと感じています。
最近のアップデートにより、AIへの指示を出すカスタムインストラクションの領域が大幅に拡張されたことで、社内特有の専門用語やプロジェクト固有のルールをAIに細かく教え込むことができるようになりました。
これにより、エンタープライズでの実用性は飛躍的に向上しています。
ただし、システムを構築して終わりではありません。
入力データの品質を保つための日々のデータクレンジングや、セキュリティポリシーの継続的な見直しが不可欠です。
本稼働させる前の最終的な導入判断やデータガバナンスについては、専門家にご相談の上、安全な環境で運用を進めてくださいね。
組織のコミュニケーションストリームにAIという知性をうまく統合することで、過去の情報探しに費やしていた無駄な時間を減らし、より創造的で価値の高い戦略的業務へと組織のエネルギーを注げるようになるはずです。
皆さんの現場の課題解決にも、この考え方が少しでも役立てば嬉しいです。ぜひ一度、小さく試してみることから始めてはいかがでしょうか。








